SenticNet is one of the emerging players in data mining software offering state-of-the-art B2B sentiment analysis services that are:
• FINE-GRAINED: because they provide detailed insights on customer preference (what product features people like/dislike)
• UNSUPERVISED: because they do not usually require training on labeled data and they are completely domain-independent
• REPRODUCIBLE: because each reasoning step of the algorithm can be explicitly recorded and replicated through each iteration
• INTERPRETABLE: because classification outputs are explicitly linked to emotions and the input concepts that convey these
• TRUSTWORTHY: because categorization results (such as positive or negative) always come with a confidence score
• EXPLAINABLE: because we employ neurosymbolic AI techniques that make the classification process fully transparent
• INTUITIVE: because we provide no-code AI tools that enable everyone to implement their ideas with no need for AI expertise
We take a multidisciplinary approach to affective computing and sentiment analysis by leveraging recent advances in knowledge representation, mathematics, commonsense reasoning, deep learning, linguistics, and psychology
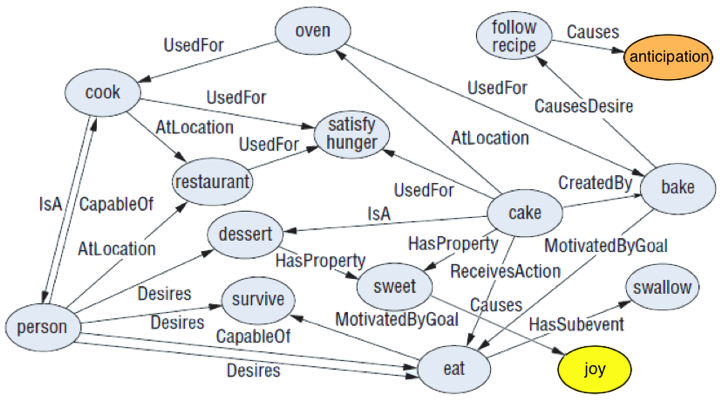
We represent commonsense knowledge as a semantic network of concepts linked to each other and to emotions via a set of semantic relationships
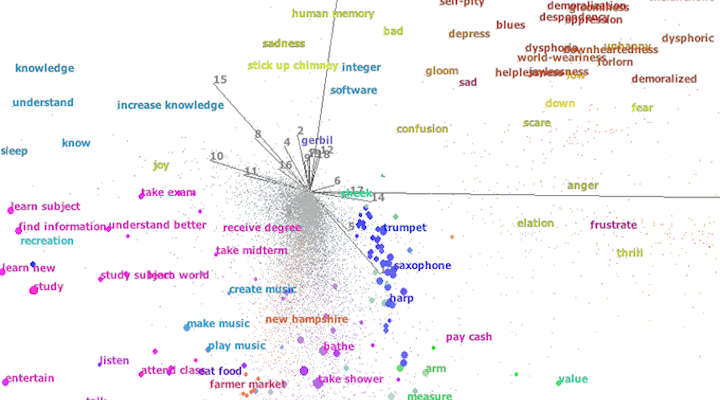
We employ different graph mining techniques and multidimensionality reduction methods for inferential and analogical reasoning
We adopt the panalogy paradigm to represent knowledge at multiple levels and shift between different reasoning strategies
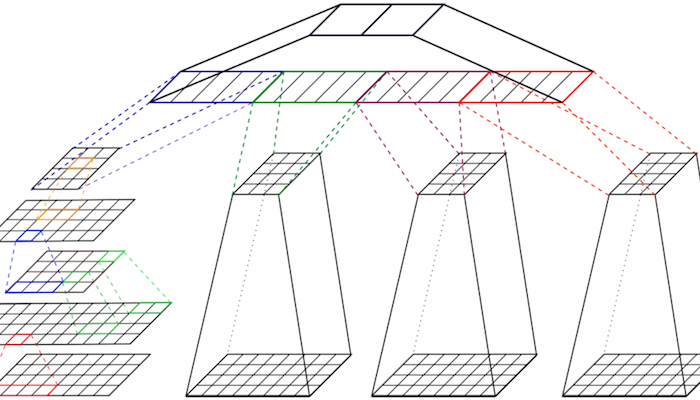
We further develop and apply the most recent deep learning techniques, e.g., Transformers, for context-sensitive emotion and sentiment analysis
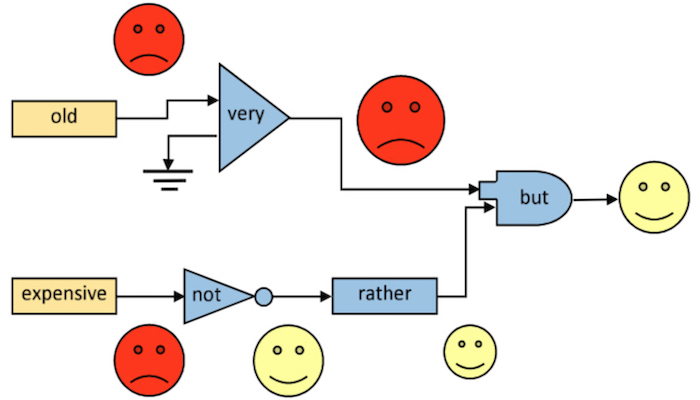
We use linguistic patterns to understand sentence structure by studying how sentiments flow throughout the different parts of the review
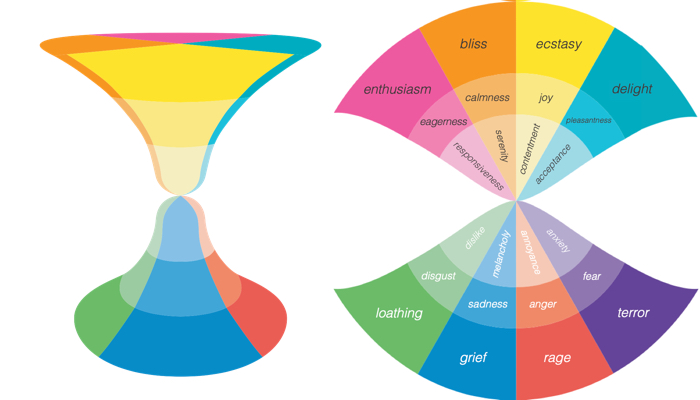
We leverage the psychology of emotions for modeling both type and intensity of emotions conveyed in text and calculate polarity based on them
The recent hype in AI has led to phenomena like AI-washing, the disingenuous act of some companies purporting their products or services to be AI-powered when in fact they are not. Moreover, several AI start-ups that have been founded recently have little to no experience about the full spectrum of AI paradigms and techniques. They may have cool websites and fancy user interfaces, but what lies underneath is often some pretty basic black-box classification algorithm.

Instead, we are a university spin-off that, since 2016, has been transforming latest technological inventions developed from university research into state-of-the-art commercial applications for affective computing and sentiment analysis. In particular, SenticNet positions itself as a horizontal technology that serves as a back-end to many different applications in several areas, including e-business, e-commerce, e-governance, e-security, e-health, e-learning, e-tourism, e-mobility, e-entertainment, etc.

Thanks to our patented AI technology, we developed a state-of-the-art neurosymbolic AI framework that employs unsupervised and reproducible subsymbolic techniques, such as auto-regressive language models and kernel methods, to build trustworthy symbolic representations that decode meaning from text, audio and video in a completely interpretable and explainable manner.

We take a holistic approach to natural language understanding by handling the many sub-problems involved in extracting meaning and polarity from text. While most works approach it as a simple categorization problem, in fact, sentiment analysis is actually a suitcase research problem that requires tackling many NLP tasks such as microtext normalization, to decode informal text, subjectivity detection, to filter out neutral content, anaphora resolution, to link pronouns with the entities of a sentence, personality recognition, for distinguishing between different personality types of the users, and more.



Sentic APIs are a suite of application programming interfaces that provide AI-as-a-service solutions for various sentiment analysis tasks. All the APIs are based on the sentic computing framework and use an ensemble of symbolic AI (SenticNet) and subsymbolic AI (deep learning). Below is a list of the APIs that are currently available. Contact us if you want to try them out or if you need a custom API for your specific data needs.
• concept parsing
• subjectivity detection
• polarity classification
• intensity ranking
• emotion recognition
• aspect extraction
• personality prediction
• sarcasm identification
• depression categorization
• toxicity spotting
• engagement measurement
• well-being assessment
CONCEPT PARSING
This API provides access to sentic parser, a tool for quickly identifying concepts from free text without requiring time-consuming phrase structure analysis. The parser employs a graph-based approach to extract 'semantic atoms' like pain_killer, go_bananas, or get_along_with, which would carry different meaning and polarity if broken down into single words.

SUBJECTIVITY DETECTION
Subjectivity detection is an important NLP task that aims to filter out ‘factual’ content from data, i.e., objective text that does not contain any opinion. This API identifies text as either objective (unopinionated) or subjective (opinionated) and handles neutrality, that is, text that is opinionated but neither positive nor negative (ambivalent stance towards the opinion target).

POLARITY CLASSIFICATION
Our most popular API. It uses an ensemble of subsymbolic techniques and SenticNet, our commonsense knowledge base, to extract polarity from text. The API also leverages sentic patterns, a set of universal linguistic rules for sentiment analysis in multiple languages, which enable the API to disambiguate difficult sentence structures and nested multiword expressions.

INTENSITY RANKING
For applications requiring finer-grained polarity classification, this API enables the inference of an intensity value to establish the degree of negativity (floating-point number between -1 and 0) or positivity (floating-point number between 0 and 1) conveyed by a piece of text. In particular, the API leverages a stacked ensemble method for ranking intensity of both emotions and sentiment.

EMOTION RECOGNITION
Several affective computing applications require the detection of emotion labels rather than a polarity label or an intensity value. This API uses the Hourglass of Emotions, a biologically-inspired and psychologically-motivated emotion categorization model for sentiment analysis, in concomitance with SenticNet and deep learning, to extract emotion labels from text.

ASPECT EXTRACTION
Aspect extraction is a fundamental step to enable aspect-based sentiment analysis, i.e., the detection of polarity with respect to different product or service features (aspects) instead of the overall polarity of the opinion. From a sentence like “the touchscreen is great but the battery lasts very little”, for example, this API extracts touchscreen as positive and battery as negative.

PERSONALITY PREDICTION
Personality can be an important factor for polarity detection. For example, a concept like go_out_drinking could be positive for extroverts but negative for introverts. This API leverages a novel transferring based multitask learning framework that predicts personality traits from text using both OCEAN and MBTI models.

SARCASM IDENTIFICATION
Polarity classification and sarcasm identification are both important NLP tasks. Sentiment is always coupled with sarcasm where intensive emotion is expressed. This API leverages a deep learning framework that models this correlation to improve the performance of both tasks in a multitask learning setting.

DEPRESSION CATEGORIZATION
Depression is a critical issue in modern society, which can sometimes turn to suicidal ideation without effective treatment. Early detection of depression from social content provides a potential way for effective social intervention. This API leverages an explainable AI model based on hierarchical attention networks to categorize depression.

TOXICITY SPOTTING
Toxicity spotting has become a serious problem in online communities and social networking sites. This API performs toxicity spotting in a multilabel environment. The proposed model extracts local features with many filters and different kernel sizes to model input words with long term dependency.

ENGAGEMENT MEASUREMENT
User engagement is important because it can predict profitability and measure the effectiveness of specific marketing campaigns. Measuring engagement can provide actionable insights into how users use or view a specific service or product. This API leverages different AI techniques for gauging polarity, intensity, and emotions to assess how engaging a target product is to users.

WELL-BEING ASSESSMENT
Subjective well-being is a broad concept related to mental health that refers to individuals' cognitive and affective evaluation of their lives. Cognitive evaluation, or self-actualization, is a self-assessment of one's own life from both positive and negative perspectives, e.g., stress. Affective evaluation is what we usually refer to as 'happiness' or the aggregation of emotions within a period of time.

Become a SenticNet Member today to enjoy unlimited access to our ever-evolving Sentic API suite, our ever-growing repository of sentiment analysis datasets and code (Sentic Archives), batch processing of big sentiment data, custom sentic.net email address, personal sentic.net homepage, members-only mailing list, bespoke customer support, early access to Sentic Labcasts, and many more perks!
🗝️ One-Month Access to Sentic APIs 100 USD
🟤 BRONZE (One-Year Membership) 1,000 USD
🪙 SILVER (Three-Year Membership) 2,000 USD
🌕 GOLD (Five-Year Membership) 3,000 USD
💎 DIAMOND (Life-Time Membership) 5,000 USD
senticnet
senticnet
senticnet

